Wiemy już, że proces optymalizacji zużycia pamięci w systemach embedded warto zacząć od przyjrzenia się pamięci mikrokontrolera oraz wyborowi narzędzi, które usprawniają proces i pomagają zadbać o bezpieczeństwo. Tym elementom poświęciliśmy pierwszą część serii artykułów o tym zagadnieniu. Czas na analizę konkretnych przypadków, w których można w optymalny sposób wykorzystać pamięć RAM.Zmienne tylko do odczytu znajdujące się w pamięci RAM
Symbole typu .data to zainicjalizowane zmienne, które są przechowywane zarówno w pamięci RAM, jak i ROM. Są one przechowywane w pamięci RAM, ponieważ pełnią funkcję zmiennych, podobnie jak symbole typu .bss. Tymczasem w pamięci ROM przechowywane są ich początkowe wartości. Z tego powodu rozmiar zmiennych typu .data należy uwzględniać podwójnie – osobno dla ROM i osobno dla RAM.
//RAM
char manufacture_name[12] = "Company Name";
//ROM
const char manufacture_name[12] = "Company Name";
Jeśli w sekcji .data widzimy dane, które podczas działania aplikacji nigdy się nie zmieniają, należy przenieść je do pamięci ROM, oznaczając zmienną jako const (stałą).
Zmienne statyczne w funkcji
Zmienne zadeklarowane w ciele funkcji zwykle lądują na stosie. Stos jest oczywiście częścią RAM, ale czas życia zmiennej na stosie kończy się po opuszczeniu funkcji. Zmienne static w ciele funkcji „żyją” przez cały czas działania aplikacji, podobnie do zmiennych globalnych, ale z ograniczonym dostępem. Jeśli nie jest to wymagane, nie warto używać zmiennych static w funkcji.
Padding, czyli dopełnienie struktury w C
Kompilator może wstawiać pomiędzy elementy struktury dodatkowe bajty, aby zapewnić wyrównanie adresów, które umożliwia szybszy dostęp do pamięci. 32-bitowe pole struktury wymaga adresu podzielnego przez 4, a 16-bitowe – adresu podzielnego przez 2. Jeśli kompilator wykryje, że kolejny element struktury znajdowałby się na miejscu z nieoptymalnym adresem, zostanie on umieszczony dalej. Nieużywane bajty pomiędzy polami struktury to padding. Nieoptymalne organizacja elementów struktury oznacza marnowanie pamięci.
//You can run this example on <https://www.onlinegdb.com/>
#include <stdio.h>
#include <stdint.h>
typedef struct
{
uint8_t sign1; // 1B
// padding 3B
uint32_t number1; // 4B
uint8_t sign2; // 1B
// padding 3B
uint32_t number2; // 4B
uint8_t sign3; // 1B
uint8_t sign4; // 1B
// padding 2B
} type_1;
typedef struct
{
uint32_t number1; // 4B
uint32_t number2; // 4B
uint8_t sign1; // 1B
uint8_t sign2; // 1B
uint8_t sign3; // 1B
uint8_t sign4; // 1B
} type_2;
int main()
{
printf("Size of type_1 is %liB\n",sizeof(type_1));
printf("Size of type_2 is %liB\n",sizeof(type_2));
return 0;
}
/* Output:
Size of type_1 is 20B
Size of type_2 is 12B
*/
W powyższym przykładzie rozmiar użytecznych danych w type_1 i type_2 jest taki sam. W ich skład wchodzą dwa elementy uint32_t oraz cztery elementy uint8_t. Rozmiar tych danych to 12B. Komentarze wskazują, gdzie znajduje się padding. Wielkość tych struktur zależy od sposobu rozmieszczenia jej członków. Przy optymalnym rozmieszczeniu type_2 ma rozmiar 12B, przy nieoptymalnym type_1 ma rozmiar 20B.
Osiem bajtów nie stanowi ogromnej straty, jednak przy dużych strukturach zła organizacja może sprawić, że będziemy tracić więcej pamięci. W szczególności gdy przechowujemy struktury w tablicach, stratę multiplikuje liczba elementów.
Atrybut „packed”
Atrybut „packed” informuje kompilator, aby nie umieszczał paddingu w strukturze. Pozornie wygląda to jak rozwiązanie problemu, ale odbywa się pewnym kosztem. Padding zapewnia wyrównanie adresów w celu przyśpieszenia dostępu do pamięci. Jego brak powoduje spowolnienie dostępu.
//You can run this example on <https://www.onlinegdb.com/>
#include <stdio.h>
#include <stdint.h>
typedef struct __attribute__((__packed__))
{
uint8_t sign1; // 1B
uint32_t number1; // 4B
uint8_t sign2; // 1B
uint32_t number2; // 4B
uint8_t sign3; // 1B
uint8_t sign4; // 1B
} type_1; //sizeof(type_1): 12B
typedef struct __attribute__((__packed__))
{
uint32_t number1; // 4B
uint32_t number2; // 4B
uint8_t sign1; // 1B
uint8_t sign2; // 1B
uint8_t sign3; // 1B
uint8_t sign4; // 1B
} type_2; //sizeof(type_2): 12B
int main()
{
printf("Size of type_1 is %liB\n",sizeof(type_1));
printf("Size of type_2 is %liB\n",sizeof(type_2));
return 0;
}
/* Output:
Size of type_1 is 12B
Size of type_2 is 12B
*/
Można jednak szybko sprawdzić, jak wiele pamięci zużywa padding. Wystarczy podmienić w plikach projektu typedef struct na typedef struct __attribute__((__packed__)) i porównać rozmiary obu wersji aplikacji. Otrzymana różnica będzie zdecydowanie wyższa od tej, którą uda się rzeczywiście otrzymać po ręcznym przeorganizowaniu struktur. Pozwoli jednak oszacować, czy warto zająć się paddingiem. Można tej metody użyć w mniejszej skali na konkretnej strukturze. Da to szybką informację zwrotną, czy warto się nią zajmować.
Dynamiczna alokacja
W systemach wbudowanych wykorzystuje się dynamiczną alokację pamięci. Przeznaczony do tego obszar pamięci określamy stertą. Jest ona w pełni zarządzana przez programistę, a jej maksymalny rozmiar jest zakładany przed kompilacją. Dobrą praktyką jest stosowanie dynamicznej alokacji tylko na etapie inicjalizacji. Pozwala to oszacować maksymalną ilość pamięci wymaganą przez aplikację do poprawnego działania oraz uniknąć fragmentacji pamięci przez ciągłą alokację i dealokację. Eliminuje to specyficzne i trudne do zreprodukowania przypadki, gdy aplikacja próbuje zaalokować pamięć, a zasoby na to nie pozwalają. W praktyce taka alokacja nie jest do końca dynamiczna – następuje w runtime’ie przy inicjalizacji, z powodu czego określamy ją dynamiczną, jednak po inicjalizacji jej rozmiar pozostaje niezmienny.
Moduły w aplikacjach wbudowanych często potrzebują własnej pamięci operacyjnej do przechowywania kontekstu lub buforów na dane, które nie mogą znajdować się na stosie. Takie dane mogą być przechowywane jako zmienne globalne albo zmienne na stercie. Warto znaleźć moduły niezależne od siebie i niedziałające w jednakowym czasie, które mogą współdzielić ten sam obszar w pamięci RAM na stercie.
Na przykład jeśli urządzenie działa w trybie wysyłania lub odbierania danych i nie jest w stanie wykonywać dwóch funkcji jednocześnie, może ono współdzielić obszar pamięci wykorzystywany do odbierania oraz wysyłania danych.
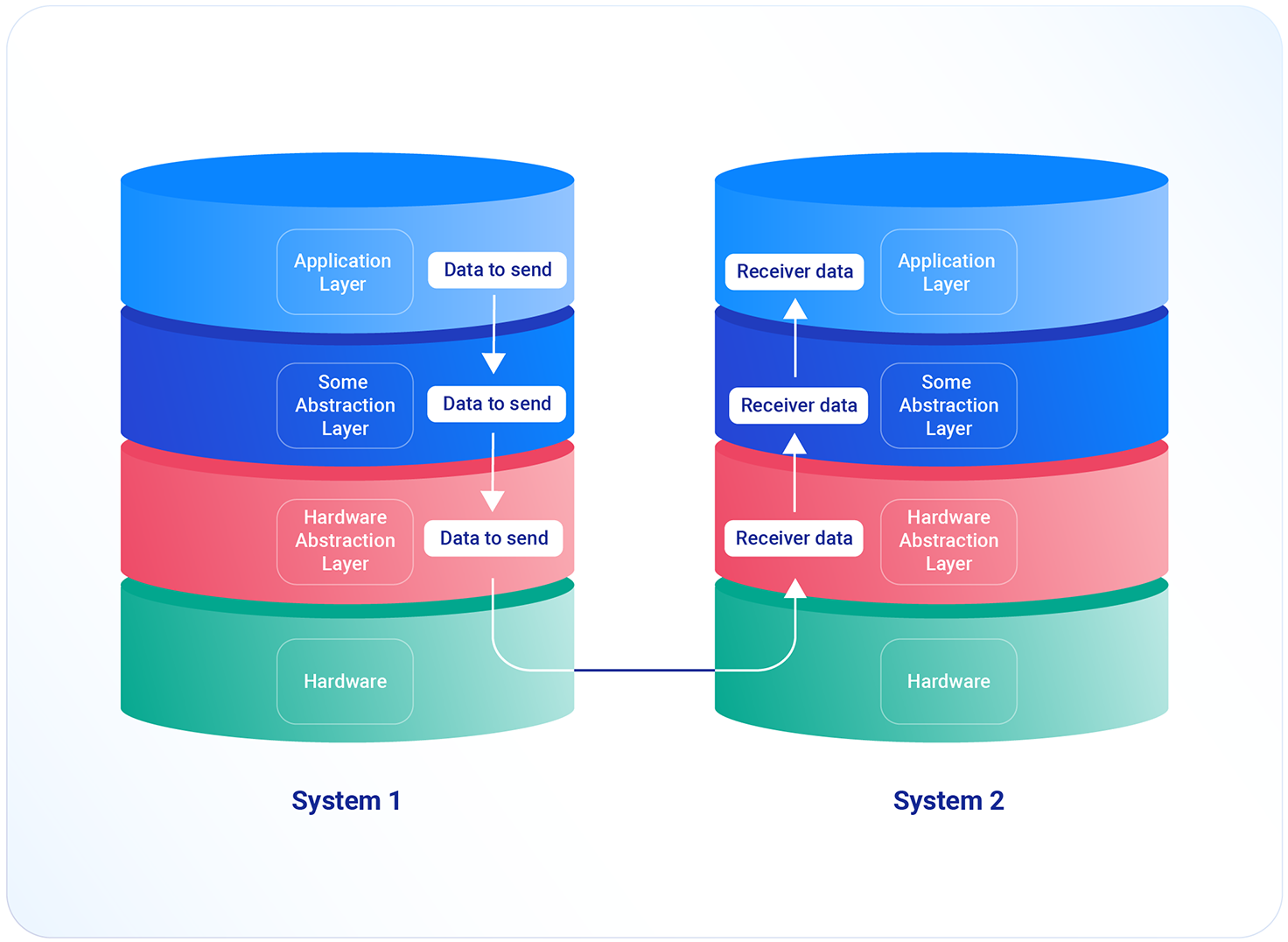
Duplikacja danych pomiędzy warstwami
Aplikacje często podzielone są na warstwy abstrakcji, które pełnią różne role. Dane są przekazywane pomiędzy warstwami. Zdarza się, że niektóre warstwy pełnią tylko funkcję pośrednika. Jeśli pozwala na to architektura aplikacji, warto zadbać, by dane pomiędzy warstwami nie były kopiowane, lecz przekazywane przez wskaźnik.
Pola bitowe „bitfields”
W języku C programista może wyspecyfikować rozmiar zmiennej w bitach. Pozwala to efektywnie wykorzystać pamięć w sytuacjach, gdy nie są wykorzystywane wszystkie bity danego typu. Skrajnym przypadkiem jest zmienna typu bool. Wystarczy jeden bit do przechowania wartości TRUE/FALSE, a w pamięci zajmuje ona cały bajt. Jedną z możliwości zaoszczędzenia paru bajtów jest skorzystanie z pól bitowych „bitfields” i pogrupowanie zmiennych tak, aby wykorzystać każdy bit pamięci.
//You can run this example on <https://www.onlinegdb.com/>
#include <stdio.h>
#include <stdbool.h>
typedef struct {
bool f0;
bool f1;
bool f2;
bool f3;
bool f4;
bool f5;
bool f6;
bool f7;
} customData_t;
typedef struct {
bool f0:1;
bool f1:1;
bool f2:1;
bool f3:1;
bool f4:1;
bool f5:1;
bool f6:1;
bool f7:1;
} customData2_t;
int main()
{
printf("Size of customData_t is %luB\n", sizeof(customData_t));
printf("Size of customData2_t is %luB\n", sizeof(customData2_t));
return 0;
}
/* Output:
Size of customData_t is 8B
Size of customData2_t is 1B
*/
Korzystanie z pól bitowych nie jest darmowe – odbywa się kosztem czasu. Potrzebna jest większa liczba instrukcji procesora do odczytywania i zmiany wartości takiego pola. Należy zatem używać tej opcji tylko w przypadkach, w których nie zależy nam na czasie wykonania operacji.
Struktury vs. unie
Warto pamiętać o różnicy pomiędzy strukturą i unią w języku C. Rozmiar struktury to suma rozmiarów wszystkich jej elementów (plus padding). Rozmiar unii jest za to determinowany rozmiarem największego jej elementu.
//You can run this example on <https://www.onlinegdb.com/>
#include <stdio.h>
#include <stdint.h>
typedef struct {
uint32_t var1;
} configurationV1_t;
typedef struct {
uint32_t var1;
uint32_t var2;
} configurationV2_t;
typedef struct {
uint32_t var1;
uint32_t var2;
uint32_t var3;
} configurationV3_t;
typedef union {
configurationV1_t confV1;
configurationV2_t confV2;
configurationV3_t confV3;
} configurationUnion_t;
typedef struct {
configurationV1_t confV1;
configurationV2_t confV2;
configurationV3_t confV3;
} configurationStruct_t;
typedef struct {
configurationUnion_t conf;
uint32_t version;
} configuration1_t;
typedef struct {
configurationStruct_t conf;
uint32_t version;
} configuration2_t;
int main()
{
printf("Size of configurationV1_t is %luB\n", sizeof(configurationV1_t));
printf("Size of configurationV2_t is %luB\n", sizeof(configurationV2_t));
printf("Size of configurationV3_t is %luB\n", sizeof(configurationV3_t));
printf("Size of configurationUnion_t is %luB\n", sizeof(configurationUnion_t));
printf("Size of configurationStruct_t is %luB\n", sizeof(configurationStruct_t));
printf("Size of configuration1_t is %luB\n", sizeof(configuration1_t));
printf("Size of configuration2_t is %luB\n", sizeof(configuration2_t));
return 0;
}
/* Output:
**Size of configurationV1_t is 4B
Size of configurationV2_t is 8B
Size of configurationV3_t is 12B
Size of configurationUnion_t is 12B
Size of configurationStruct_t is 24B
Size of configuration1_t is 16B
Size of configuration2_t is 28B**
*/
Miejscem, w którym można zauważyć przewagę unii nad strukturą jest np. przechowywanie danych urządzenia z uwzględnieniem kompatybilności wstecznej. Wraz z rozwojem produktu przybywa funkcji w aplikacji. Dobry ekosystem powinien być kompatybilny z urządzeniami starszych generacji. By obsłużyć każde z urządzeń, potrzeba pamięci na największy możliwy kontekst.
Do takiego zastosowania unia sprawdzi się idealnie. Na powyższym przykładzie widzimy przykład przechowywania konfiguracji zależnych od wersji z wykorzystaniem unii i struktur. configuration1_t wykorzystuje unię, a configuration2_t strukturę. Logikę aplikacji należy uzależnić od wartości zmiennej version.
Głębokość stosu
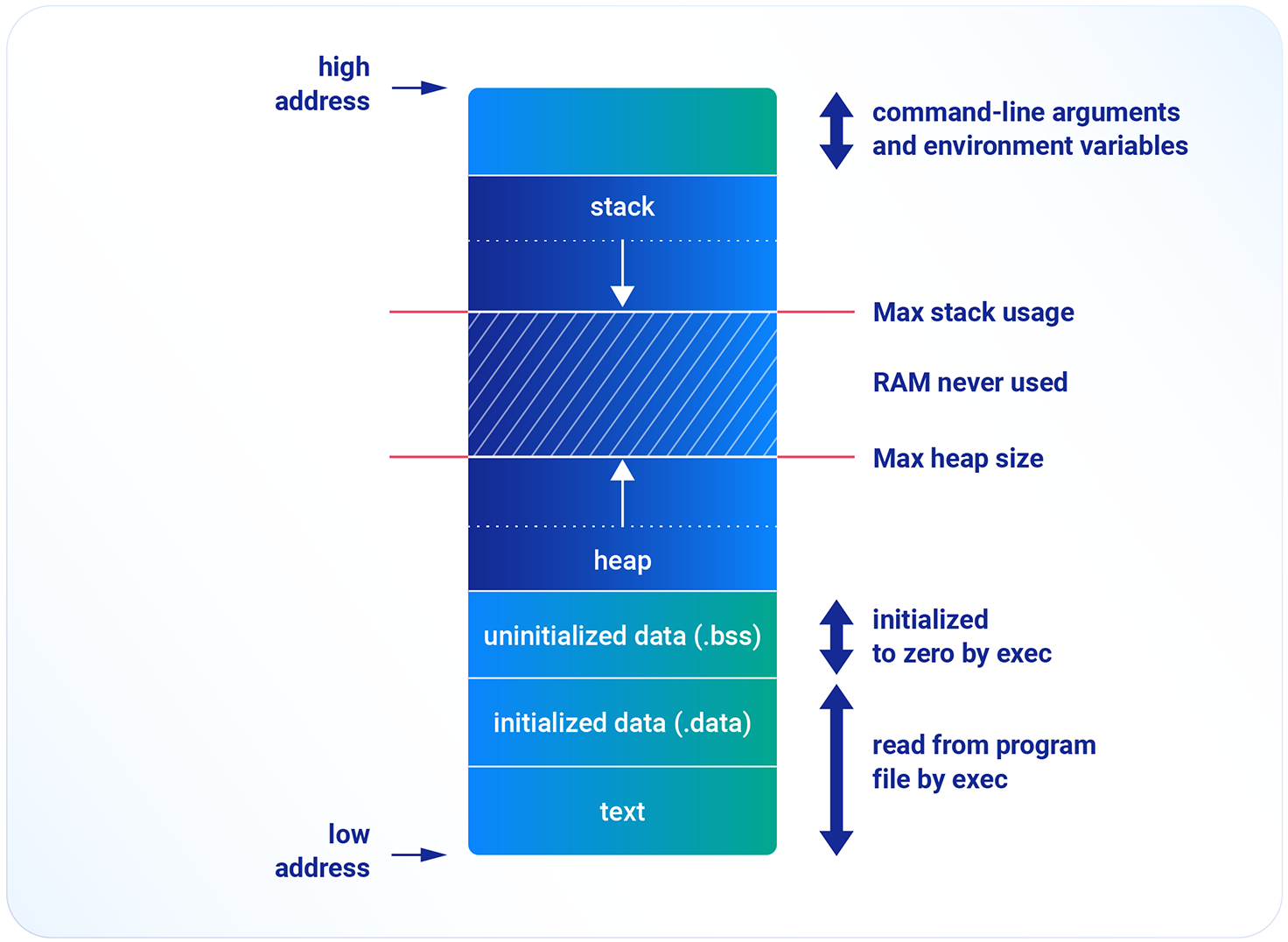
Stos, sterta, .bss oraz .data są częścią RAMu. Jeśli w aplikacji brakuje pamięci na zmienne globalne (.bss i .data) lub na dynamiczną alokację (sterta), należy zastanowić się nad modyfikacją ilości pamięci przeznaczonej na stos.
Stos jest pamięcią operacyjną wykorzystywaną przez program do przechowywania miedzy innymi zmiennych lokalnych, argumentów funkcji oraz ramek stosu. Programista definiuje jego maksymalny rozmiar. Dobrą praktyką jest pomiar głębokości stosu, czyli minimalnego rozmiaru pozwalającego na poprawne działanie aplikacji. Taki pomiar pozwoli na bezpieczne zmniejszenie rozmiaru stosu na rzecz sterty lub przestrzeni zmiennych.
GCC pozwala na statyczną analizę stosu dzięki fladze --fstack-usage. W ten sposób programista może otrzymać informacje o utylizacji stosu przez każdą funkcję osobno. Niestety dla tej metody jedne funkcje mogą wywoływać kolejne, co powoduje, że przy skomplikowanych systemach nie jesteśmy w stanie oszacować maksymalnego zużycia stosu.
Metodą umożliwiającą oszacowanie maksymalnego zużycia stosu jest tak zwany „stack painting”. Polega ona na wypełnieniu pamięci stosu znanym ciągiem danych. Następnie należy wykonać zestaw operacji systemu, które chcemy poddać analizie, odczytać pamięć i sprawdzić, jaka część została nadpisana.
Jeśli zmierzona maksymalna głębokość stosu jest zbyt duża, można podjąć próbę optymalizacji. GDB pozwala na odczyt aktualnego wskaźnika stosu. Można z wykorzystaniem debuggera przejść cały kod krok po kroku (single-stepping) i obliczać rozmiar stosu linijka po linijce. To dokładna metoda pozwalająca wykryć ekstrema, od których warto zacząć optymalizację.
Chcąc zmniejszyć zużycie stosu przez wywoływane funkcje, można wykorzystać kilka sposobów:
- Zamiana zmiennych lokalnych funkcji na zmienne statyczne lub globalne. Spowoduje to przeniesienie zmiennej ze stosu do sekcji .bss, zmniejszając zużycie stosu kosztem sekcji .bss
- Dynamiczna alokacja zmiennych lokalnych funkcji (jeśli aplikacja korzysta z dynamicznej alokacji pamięci). Spowoduje to umieszczenie ich na stercie. Pamięć przeznaczona na dynamiczną alokację jest zarezerwowana na stercie, więc jeśli nie jest wykorzystywana przez inne moduły, warto z niej korzystać
- Wykorzystanie funkcji inline. Każde wywołanie funkcji wiąże się ze stworzeniem ramki stosu, która zawiera informacje potrzebne do działania funkcji. Wykorzystanie funkcji inline spowoduje redukcję liczby wywołań funkcji, a co za tym idzie, zmniejszenie obciążenia stosu
- Przekazanie dużej struktury do funkcji przez wskaźnik. Argumenty funkcji również trafiają na stos, dlatego przekazywanie przez wskaźnik jest zazwyczaj lepszym rozwiązaniem. Zmniejsza zużycie stosu, ponieważ wskaźnik zwykle ma mniejszy rozmiar niż struktura (4 bajty w architekturze 32-bitowej). Poprawia to również wydajność, ponieważ przekopiowanie wskaźnika na stos będzie szybsze niż kopiowanie struktury.
Podsumowanie
Optymalizacja struktur, mądre zarządzanie stertą, minimalizacja zużycia stosu oraz inne opisane wyżej metody to sprawdzone sposoby optymalizacji zużycia pamięci RAM. Ze względu na ograniczone zasoby warto o nich pamiętać podczas pracy nad systemami wbudowanymi. W trzeciej części przyjrzymy się kolejnym możliwościom optymalizacji, tym razem z pomocą pamięci ROM.