O tym, ile problemów i frustracji sprawia niedbale napisany kod, wie chyba każdy programista. Nie wszyscy jednak wiedzą, jak napisać clean code i czym właściwie powinien się on charakteryzować. Artykuł ten jest obowiązkową pozycją dla każdego, kto chce poznać techniki rzetelnego i efektywnego programowania.
Wstęp
Zapewne każdy programista spotkał się z niechlujnym kodem tracąc mnóstwo czasu na przedarcie się przez niezrozumiałe nazwy zmiennych, pokręconą strukturę programu i ukryte zachowania metod. Taki bałagan spowalnia pracę, rodzi frustrację i budzi w pewnym sensie strach do wprowadzania jakichkolwiek zmian. To wszystko znacząco zwiększa koszt produkcji oprogramowania. Każda nowa funkcjonalność, modyfikacja systemu, wymaga zrozumienia tych poplątanych, tajemniczych gałęzi zabierając programiście bardzo dużo czasu. Z dużym prawdopodobieństwem zmiany w złym kodzie wprowadzają błędy w innych fragmentach kodu, które wymagają ponownej analizy i ostatecznie bug fixing’u. Jest to klasyczny przykład regresji, coś, co wcześniej działało nagle przestało działać. Przeważnie bałagan rodzi jeszcze większy bałagan, który mocno obniża efektywność zespołu i z czasem staje się niemożliwy do „posprzątania”. W konsekwencji niechlujny kod doprowadza do marazmu projektu, a w najgorszym przypadku do upadku firmy. Przeczytaj także artykuł o najpopularniejszych językach programowania.
Dlaczego taki kod powstaje?
Może to być spowodowane brakiem wiedzy na temat czystego kodu, brakiem świadomości czym skutkuje zły kod, brakiem doświadczenia programisty, który widzi, że kod jest niechlujny - zdaje sobie sprawę z konsekwencji, ale nie ma pomysłu jak go poprawić. Można to porównać do malowania obrazu. Większość osób jest w stanie stwierdzić czy obraz jest ładny, czy brzydki, ale nie oznacza to, że wie jak malować. Kolejnymi prawdopodobnie najczęstszymi przyczynami wprowadzania bałaganu w kodzie są pośpiech, goniące terminy i presja szefostwa. Jest to niestety pułapka, w którą dość często wpadają programiści, ponieważ nie da się dotrzymać terminów, pisząc zły kod. Profesjonalny programista doskonale wie, że bałagan w kodzie natychmiast go spowalnia, a to w dużej mierze powoduje przekroczenie terminów. Czysty kod to główna droga do sukcesu, do dotrzymywania terminów, do trzymania wysokiej jakości oprogramowania i przede wszystkim szybkiego rozwoju aplikacji. Programista powinien bronić kod z wielką pasją tak samo jak z wielką pasją szef broni harmonogramu.
Jak stwierdzić czy kod jest niechlujny?
Najczęściej spotykaną metryką, która pokazuje czy kod jest zły, to ilość wypowiedzianych WTF na minutę podczas jego czytania. Im więcej WTF tym kod jest bardziej niechlujny. Dodatkowo z pomocą przychodzą różne narzędzia jak np. Sonarqube, które na podstawie automatycznej analizy statycznej kodu i zdefiniowanych reguł potrafią ukazać w przejrzysty sposób mankamenty i nieczystości w kodzie. Są to jednak maszyny, które powinny oczywiście w pierwszej kolejności dać feedback programiście, ale najlepszą oceną kodu jest ocena innych doświadczonych programistów, którzy „czują kod”, znają i potrafią stosować zasady czystego kodu oraz nie na jednej aplikacji zęby zjedli.
Co to jest clean code?
Każdy programista ma pewnie swoją definicję czystego kodu, natomiast myślę, że idea powinna być taka sama. Czysty kod powinien być:
- czytelny, samo-komentujący się, uporządkowany. Często porównuje się go do dobrego artykułu. Jest wstęp, który niesie ogólną informację, o czym ten artykuł jest, są sugestywne, zrozumiałe nagłówki z kilkoma akapitami, które segregują myśli i wątki w taki sposób, że artykuł przyjemnie się czyta. Przekładając to na kod, nagłówki to klasy, akapity to metody a zdania to instrukcję,
- prosty implementacyjnie, krótki, bez tajemniczych sztuczek, które nie dają żadnych wartości,
- poddawany testom – wszystkie testy powinny przechodzić prawidłowo,
- solidny – budzi zaufanie, jest intuicyjny, spełnia zasady SOLID.
Jak pisać czysty kod?
Należy sobie uświadomić, że nie ma idealnego kodu. Kod może być co najwyżej najczystszy i najlepszy, jaki mógł zostać wykonany w danym momencie. Napisanie takiego kodu wymaga umiejętności zdobytej poprzez ciężką pracę i praktykę bazując na wiedzy z dziedziny programowania, znajomości zasad, wzorców i heurystyk clean code’u.
Poniżej przedstawiam 15 podstawowych reguł jak pisać czysty kod:
1. Opisowe nazwy
Nazwy zmiennych, metod i klas powinny być opisowe, powinny przedstawiać intencje, informować, w jakim celu istnieją, co robią, jak są używane.
Poniżej przykład nieczytelnego kodu. Pojawiają się magiczne liczby (0, 1), nic niemówiące nazwy (l, PTLights, m1). Dodatkowo nazwa zmiennej wprowadza dezinformację polegającą na tym, że mała litera L wygląda bardzo podobnie do cyfry 1.

Wyniesienie magicznych liczb do stałych i wprowadzenie odpowiednich nazw klasy, pola i metody znacząco poprawia czytelność. Przykładowe rozwiązanie:
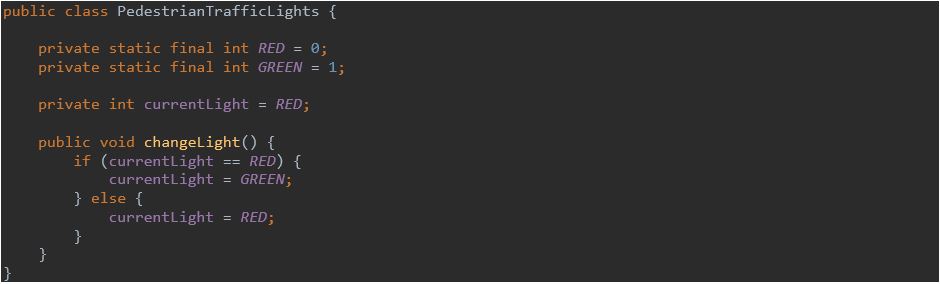
2. Nazwy na odpowiednim poziomie abstrakcji
Nazwy mogą być opisowe, jednak mogą mówić za mało, lub za dużo na konkretnym poziomie abstrakcji. Przykładowo:

Zmienna csvPath jasno mówi, że jest to ścieżka do pliku CSV, ale pojawiają się pytania, czy tylko pliki CSV mogą być kompresowane? Czy pliki mogą być kompresowane tylko do formatu ZIP? Takie nazwy ograniczają użycie tej metody tylko do kompresji plików CSV w formacie ZIP. Co prawda ograniczenie to jest tylko na poziomie kontekstu, jednak sprawia, że metoda może być rzadziej używana. Dodatkowo mogą powstać bardzo podobne metody do kompresji innych plików w innych formatach. W tym przypadku lepszą nazwą metody będzie compress a zmiennej filePath.
3. Nazwy powinny opisywać efekty uboczne
Nazwa powinna opisywać, co wykonuje dana metoda, zmienna lub klasa. Przykładowo, jeżeli funkcja wyszukuje jakiś obiekt a w przypadku kiedy go nie znajdzie tworzy nowy to lepiej użyć nazwy findOrCreate zamiast tylko find.
4. Komentarze nie powinny istnieć
Pisanie komentarzy w kodzie przeważnie spowodowane jest tym, że nazwy zmiennych, metod i klas są nieczytelne lub niepoprawne. Zamiast je tworzyć, lepiej poświęć czas na wyborze odpowiednich nazw. Jeśli napisanie komentarza jest rzeczywiście uzasadnione, to trzeba napisać go dobrze. Powinien być zwięzły, gramatycznie poprawny z uważnie dobranymi słowami.
5. Zakomentowany kod powinien być usunięty
Zakomentowany kod rodzi sporo pytań czytelnika, w ogólności zanieczyszcza cały kod i przeszkadza w czytaniu. Im dłużej istnieje, tym bardziej się psuje i traci na znaczeniu. Dodatkowo możliwe, że nikt go nie skasuje, bo nie będzie wiedział, czy jest on znaczący, czy nie, czy ktoś go potrzebuje, czy ma wobec niego jakieś plany. Zakomentowany kod powinien być zawsze usuwany.
6. Formatowanie kodu zgodnie z zasadami zespołowymi
Pracując w zespole, nie należy stosować własnych ulubionych zasad formatowania. To zespól programistów ustala jeden styl formatowania i każdy powinien się do niego dostosować. Kod musi być spójny, musi budzić zaufanie czytelnika, który uzna, że formatowanie w jednym pliku źródłowym oznacza to samo w innym.
7. Funkcje powinny być małe wykonując jedną czynność
Wielkość funkcji można zmierzyć po ilości wierszy, z których jest zbudowana. Im więcej wierszy tym funkcja bardziej nieczytelna i trudniej zrozumieć jej działanie. Małe funkcje to te, które skonstruowane są maksymalnie z 20 wierszy wykonując tylko jedną operację. Jeśli wierszy jest więcej, to prawdopodobnie funkcja wykonuje więcej czynności.

Powyższy kod nie jest długi natomiast widać, że wykonuje kilka czynności: pobiera relacje, kasuje każdą relację, loguje informacje o wykasowaniu relacji oraz kasuje samochód. Można to poprawić następująco:

W tym przypadku również łatwo wykazać, że funkcja wykonuje trzy czynności, natomiast należy zwrócić uwagę, że te trzy kroki znajdują się o jeden poziom abstrakcji poniżej zadeklarowanej nazwy funkcji i to świadczy o tym, że funkcja wykonuje tylko jedną operację.
8. Jak najmniejsza liczba argumentów funkcji
Argumenty funkcji są kłopotliwe i utrudniają zrozumienie funkcji. Najlepiej konstruować funkcje bezargumentowe, później jednoargumentowe i dwuargumentowe. Funkcji trzyargumentowych należy unikać, a funkcje wieloargumentowe (więcej niż 3 argumenty) nie powinny być stosowane. Przykładowo funkcja writeText(text) jest łatwiejsza w zrozumieniu niż writeText(outputStream, text). W tej sytuacji argumentu outputStream można się pozbyć definiując je jako pole klasy. Gdy funkcja wymaga wiele argumentów, to prawdopodobnie niektóre z nich można umieścić w osobnej klasie. Przykładowo:

można zastąpić

9. Funkcje nie powinny zwracać null
Zwracanie wartości null tworzy dodatkową pracę i powoduje problemy w funkcjach wywołujących. W takich przypadkach przez brak sprawdzenia wartości null traci się kontrolę nad aplikacją. Pojawiają się wyjątki NullPointerException, które w najmniej oczekiwanym czasie przerywają działanie programu. W poniższym przykładzie:

zamiast zwracać null w metodzie getCars() lepiej zwrócić pustą listę…
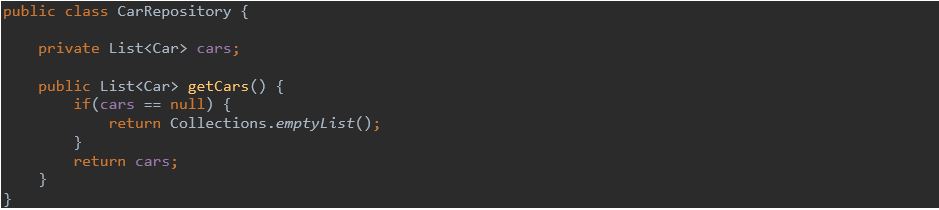
10. Rozdzielanie poleceń i zapytań
Funkcja powinna wykonywać jakieś polecenie lub odpowiadać na jakieś pytanie. Nie powinna robić tych dwóch operacji jednocześnie, ponieważ często prowadzi to do pomyłek. Przykładowo poniższa funkcja:

ustawia wartość na podanym atrybucie i zwraca true w przypadku powodzenia i false jeśli taki atrybut nie istnieje. Powoduje to powstanie dziwnych instrukcji jak np.:

Pojawiają się tu pytania, co ta funkcja dokładnie robi? Czy sprawdza, czy atrybut „title” miał wcześniej ustawioną wartość „Clean Code”? Czy udało się ustawić wartość „Clean Code” na atrybucie „title”? W tym przypadku słowo „set” może być czasownikiem lub przymiotnikiem, co utrudnia wywnioskowanie znaczenia z wywołania tej metody.
Rozwiązaniem tej zagadki jest oddzielenie polecenia od zapytania, dzięki czemu niejasność nie występuje.

11. Zasada DRY (Don’t repeat yourself)
Reguła DRY zaleca unikanie różnego rodzaju powtórzeń wykonywanych przez programistów podczas wytwarzania oprogramowania. Odnosząc się do kodu, chodzi o niewklejanie, lub niepisanie tych samych, lub bardzo podobnych fragmentów kodu w różnych miejscach. Takie powielanie kodu powoduje jego wzrost, wymaga tych samych modyfikacji w kilku miejscach w przypadku jakichkolwiek zmian algorytmu, a to z kolei zwiększa możliwość popełnienia błędu.
Najprostsze rozwiązanie na zduplikowany kod to wyniesienie go do osobnej metody. W niektórych przypadkach pomaga zastosowanie polimorfizmu lub wzorców projektowych jak np. szablon metody, lub strategia.
12. Obsługa błędów powinna być jedną operacją
Obsługa błędów jest jedną operacją i zgodnie z zasadą pojedynczej odpowiedzialności funkcja obsługi błędów nie powinna wykonywać nic innego. Oznacza to, że słowo kluczowe try powinno być pierwszym słowem w funkcji i nie powinno się w niej znajdować nic oprócz catch i finally.
Zły kod:
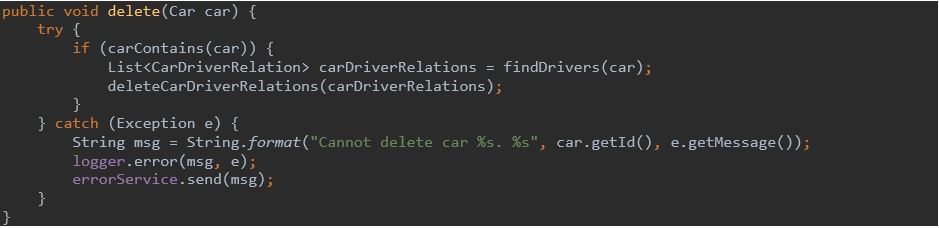
Poprawiony kod:
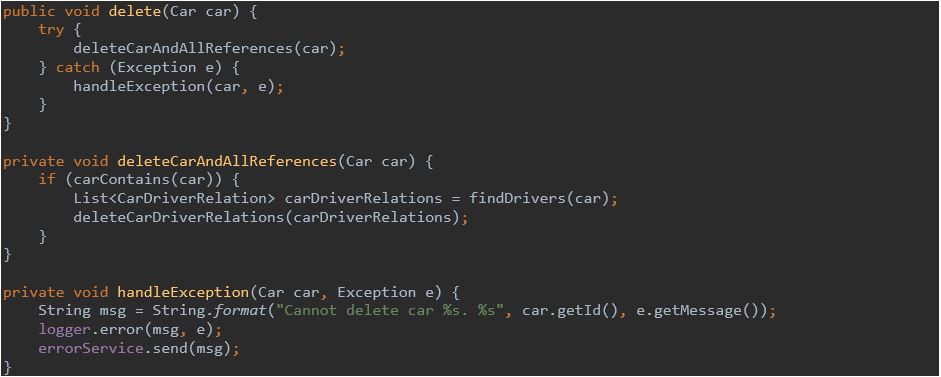
13. Klasy powinny mieć jedną odpowiedzialność
Zgodnie z zasadą pojedynczej odpowiedzialności (SRP), klasa powinna mieć tylko jeden powód do zmiany. Jeżeli klasa jest odpowiedzialna za więcej niż jeden obszar w naszej aplikacji, to może powodować to problemy w przyszłości tzn. robiąc zmiany w jednym obszarze, można zepsuć coś w innym obszarze, który wydaje się niepowiązany.

W powyższym przykładzie klasa FileCompressor ma więcej niż jedną odpowiedzialność. Po pierwsze kompresuje plik, po drugie tworzy katalog. Aby FileCompressor spełniała zasadę SRP należy wynieść metodą createDirectory do osobnej klasy np. DirectoryCreator.
14. Hermetyzacja – zmienne i funkcje użytkowe pozostają prywatne
Najczęściej zmienne i funkcje użytkowe w klasach powinny być prywatne. Takie ukrywanie dostępność dla innych klas sprawia, że refaktoryzacja jest bezpieczniejsza a zmiana stanu obiektu w pełni kontrolowana. Czasami zmiennym, lub funkcjom zmienia się zasięg na chroniony lub dostępny w ramach pakietu. Jest to głównie wymuszone przez testy, w sytuacji kiedy test potrzebuje wywołać taką funkcję, lub odnieść się do zmiennej. Należy jednak w pierwszej kolejności szukać sposobu na zachowanie prywatności.
15. Spójność klasy powinna być wysoka
Klasa, w której każda zmienna instancyjna jest wykorzystywana w każdej metodzie, jest maksymalnie spójna. Zwykle nie jest możliwe tworzenie takich klas, ale należy dążyć do tego, aby spójność była wysoka. Dzięki temu metody i zmienne klasy są wzajemnie zależne i tworzą logiczną całość.
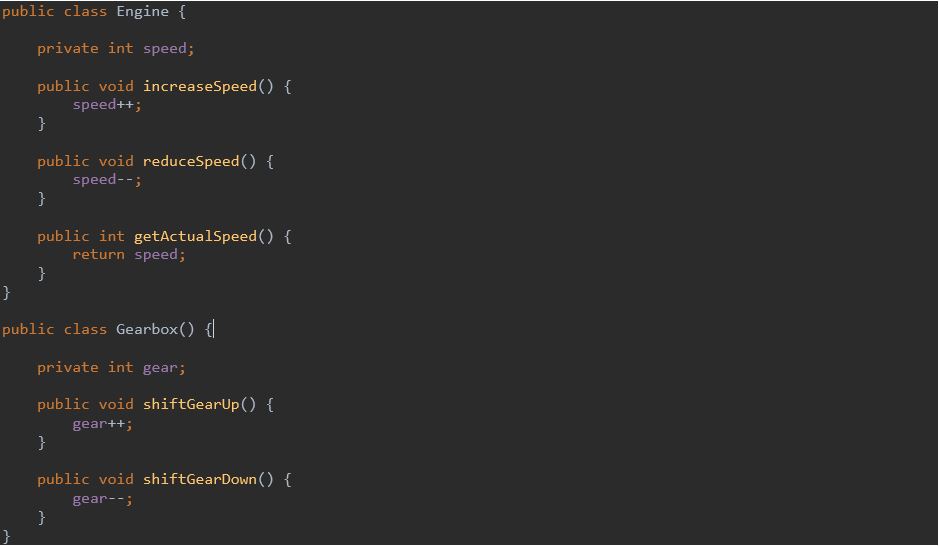
Przy stosowaniu małych funkcji z małą liczbą parametrów często można zaobserwować, że niektóre zmienne instancyjne używane są tylko przez podzbiór metod. W tym przypadku oznacza to, że w takiej klasie istnieje inna klasa, która powinna być od niej uwolniona. Dzięki temu powstałe klasy będą bardziej spójne. Przykładowo:
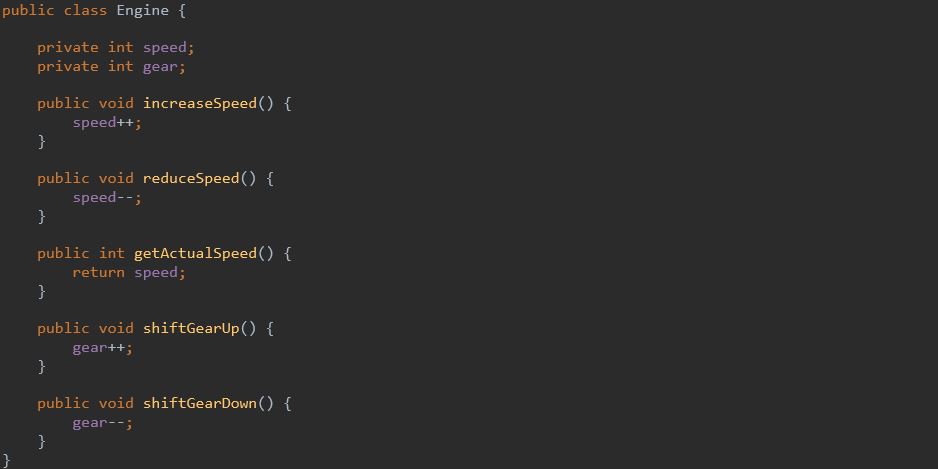
Klasa Engine ma pole gear, które jest używane tylko w dwóch metodach shiftGearUp i shiftGearDown. Dzięki tej obserwacji możemy utworzyć nową klasę Gearbox, a tym samym uzyskać wysoką spójność klasy Engine i Gearbox. Dodatkowo te klasy uzyskały jedną odpowiedzialność.
Podsumowanie
Clean code to fundament dobrej aplikacji, którą łatwo się utrzymuje i rozszerza o nowe funkcjonalności. Pisanie czystego kodu wymaga wiedzy, praktyki i asertywności a przedstawione tutaj zasady to tylko kropla w morzu reguł clean code’u. Natomiast stosowanie ich jest pierwszym krokiem do podniesienia jakości i czytelności naszego kodu:
- Wybór opisowych nazw klas, funkcji i zmiennych
- Nazwy powinny być na odpowiednim poziomie abstrakcji
- Nazwy powinny opisywać efekty uboczne
- Nie należy stosować komentarzy. Kod powinien być samo opisujący się
- Zakomentowany kod powinien być usunięty
- Formatowanie kodu powinno być zgodne z zasadami przyjętymi w zespole
- Funkcje powinny być małe wykonując jedną czynność
- Funkcje powinny przyjmować maksymalnie 3 argumenty. Im mniej, tym lepiej
- Funkcje nie powinny zwracać null
- Funkcje powinny wykonywać albo jakieś polecenie, albo odpowiadać na jakieś pytanie
- Stosowanie zasady DRY
- Obsługa błędów powinna być jedną operacją
- Klasy powinny mieć jedną odpowiedzialność
- Zmienne i funkcje użytkowe powinny być prywatne
- Spójność klasy powinna być wysoka
- Kod powinien być pokryty testami jednostkowymi
- Programowanie obiektowe powinno spełniać założenia SOLID
Zapraszamy rónież do inspirującej rozmowy "Od programowania do pierwszej linii wsparcia".